Connect with us
ウェルグリーン・アイ株式会社
― WGIのAI・DXにより高品質な遺伝子発現データを構築・駆使し、遺伝子を高精度・迅速に同定 ―
◆ 以下の文章中の「Task」のあとのアルファベット(例:
Task A
)は、
問い合わせフォーム
の「依頼内容」の記号(A~Q)に対応しています。
遺伝子発現情報から高精度・迅速に遺伝子を探索するためのWGIの独自技術
WGIは、遺伝子同定などのための受託解析サービスを提供しています。
WGIは、遺伝子発現情報を用いた遺伝子探索に多数の
経験と実績
を有します。
遺伝子探索のために、WGI独自のAI・DX・バイオインフォマティクス解析基盤を構築するとともに、高品質ビッグデータを整備しています。
WGIの解析手法は、従来法とは異なるアプローチに基づくため、従来法の問題点にとらわれることなく、高精度・高速な遺伝子探索を可能としています。
大規模な遺伝子発現データも容易にハンドリングできます。
トランスクリプトーム解析の基盤情報:遺伝子発現行列と遺伝子発現プロファイル
◆トランスクリプトーム解析と遺伝子発現行列からのDEG探索
トランスクリプトーム解析は、研究対象の形質(環境応答や時系列実験を含む)に関連する候補遺伝子を探索するための主要なアプローチです。
トランスクリプトーム解析により、ゲノムワイドな遺伝子の発現量(トランスクリプトーム情報)が得られます。
複数の異なる実験条件(対照実験など)からで得られた発現量をまとめて、
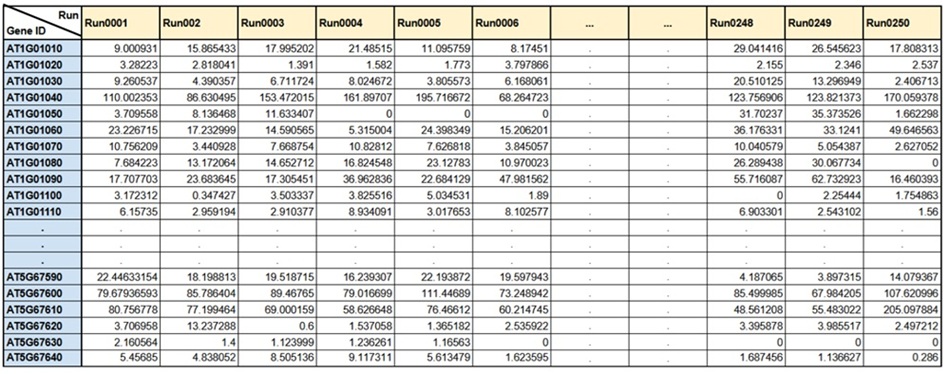
遺伝子発現行列
が得られます(下表参照)。
続きはこちら...
遺伝子発現行列
は、行に各遺伝子、列に各実験サンプル(検体、Run)、要素に遺伝子発現量を記述します。
遺伝子発現行列
から、実験条件の違いに応じて
発現量が変動する遺伝子群(DEG:Differentially Expressed Gene)
を選抜できます。
DEG群は遺伝子の集合であり、研究対象としている
形質を支配する遺伝子を含むと期待
できます。
ゲノムワイドな遺伝子の発現量を調査する解析プラットフォームの進化により、トランスクリプトーム情報の質と量は著しく向上しています。
An Example of the Gene Expression Matrix(Unit: TPM)
◆遺伝子発現行列からの遺伝子発現プロファイルの取得
遺伝子発現行列の各行(行ベクトル)
は、それぞれの遺伝子の全列(全Run: 実験条件)に渡る発現量の変動を表しており、
遺伝子発現プロファイル
として可視化できます(下図参照)。
続きはこちら...
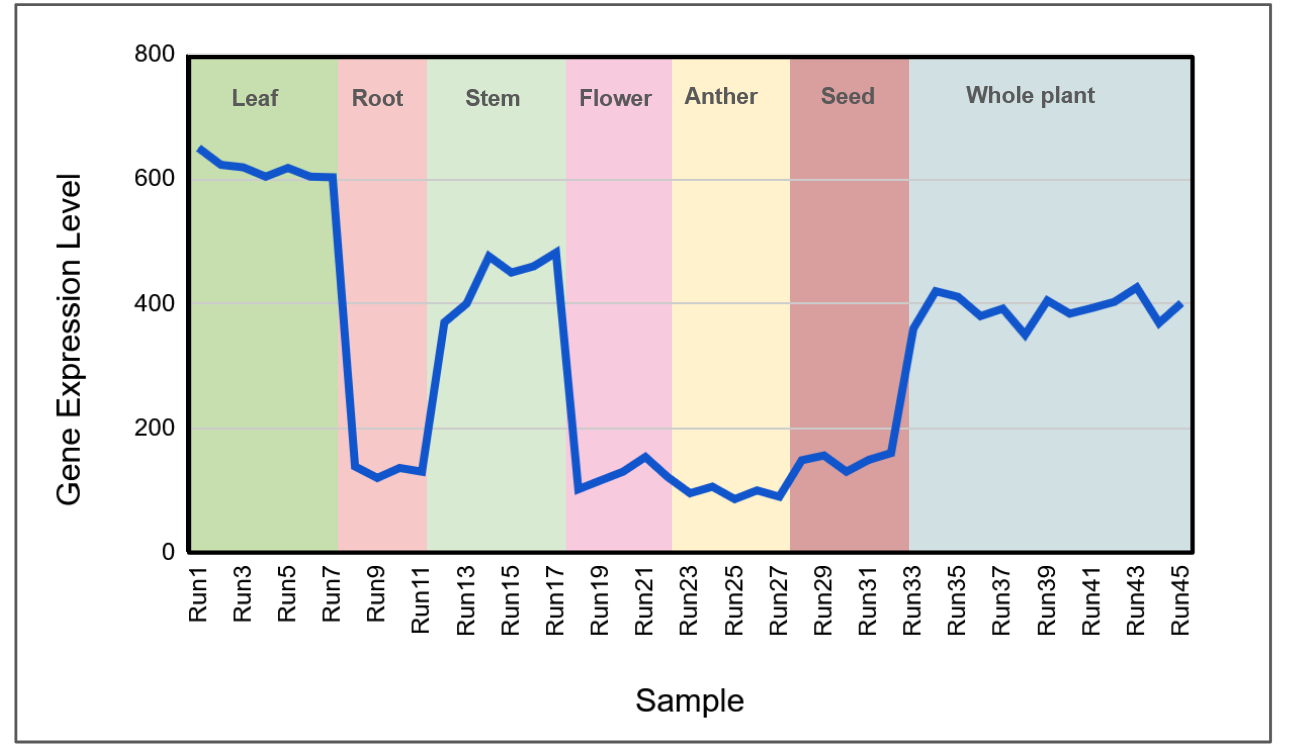
遺伝子発現プロファイルは、横軸が実験条件(サンプル、検体、Run:行列の各列)、縦軸が発現量であり、
1つの遺伝子の発現量を1つの折れ線で描画
します。
遺伝子発現プロファイルを閲覧することにより、
高発現・低発現する条件の把握
が容易となります。
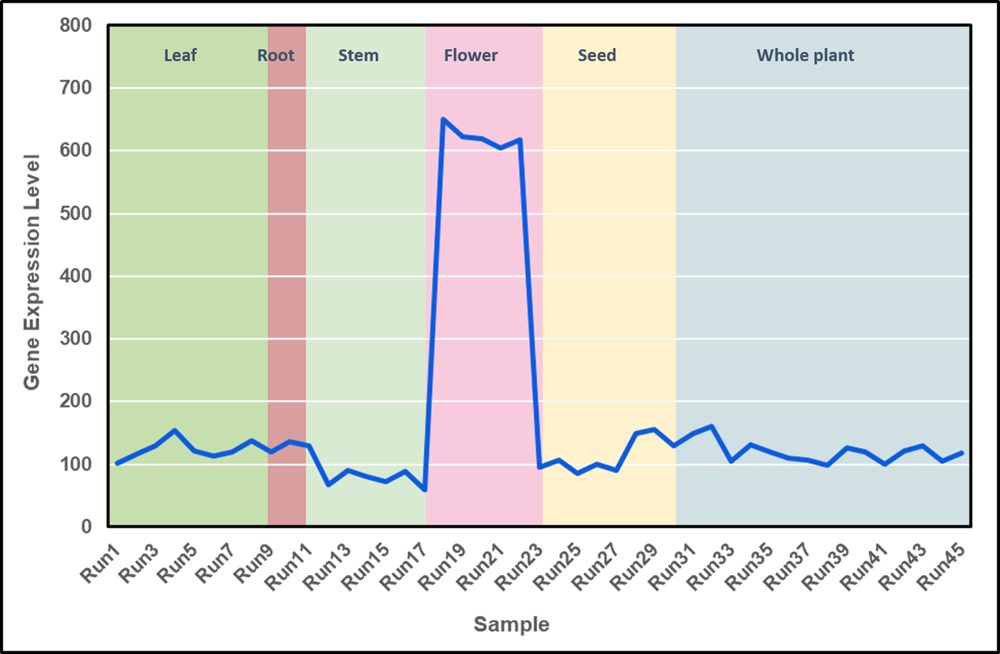
下図に示す遺伝子の
発現プロファイル
では、横軸のサンプルをRNAの抽出した器官別に並べており、葉と茎で発現量が高い傾向にあることが直ちに把握できます。
遺伝子発現プロファイルを遺伝子間で比較することにより、
発現プロファイルに基づく遺伝子分類
が可能となります。
An Example of the Gene Profile
遺伝子発現行列
と
遺伝子発現プロファイル
を活用することにより、様々な遺伝子の探索が可能となります。
WGIでは、遺伝子発現行列から生物学的知見を高精度・迅速に導出する受託解析サービスを提供するために、最先端の独自のトランスクリプトーム解析基盤を構築しています。
RNA-Seqビッグデータのメタデータ化による遺伝子探索の高精度化・高速化・低コスト化(Task D)
オンライン上のRNA-seqビッグデータを十分に活用できない
オンラインデータベースには膨大なRNA-seq実験データが登録・公開
されており、学術的に高い価値があります。
これらの実験データを駆使することで、多様な
遺伝子の同定などが加速化
すると期待されます。
その一方で、RNAのサンプリング条件(実験条件)の記述がデータ登録者に委ねられているため、
Webページでの実験条件の記述の質と量は玉石混交
です。
続きはこちら...
各実験の実験要件をWebページの記述から詳細かつ容易に把握することも時間的・労力的に困難
です。
また、
実験条件の記述に用いられている用語も研究者間で必ずしも同一ではありません
。
そのため、解析対象とするRNA-seq実験データを
データベースから正確かつ網羅的に検索することが困難
です。
データベースからダウンロードした多数の実験データを用いて興味のある処理条件(例:生育ステージ)で比較解析する際に、 それ以外の条件(例:材料やRNA抽出部位、生育条件、シークエンシングのプラットフォーム)の
同一性の確認も困難
です。
これらの制約から、オンライン上の登録データを効果的・効率的に活用できません。
◆オンライン上のRNA-seq実験データのメタデータ整備による高品質ビッグデータ生成
RNA-seqの実験条件の項目は、材料(系統・品種)、生育ステージ、部位、時刻、生育環境など多岐にわたります。
データベースから取得したRNA-seqデータの
実験条件をすべて把握することは時間的・労力的に困難
です。
続きはこちら...
また、データベースの関連ページに、実験条件が詳細に記述されているとは限りません。
たとえば、データベースから、処理が異なる実験データ(例:ある薬品の投与量)と対照区となるRNA-seq実験データを取得し、比較解析する場合、実験データ数が多いほど、DEGを高精度に抽出できます。
しかし、着目している処理以外の条件、たとえば、用いられている材料(系統、品種、ノックアウト変異体、交雑後代など)や生育条件が大きく異なる実験データが混在していると、DEG群を正確に選抜できなくなります。
そのため、データベースから解析対象とする実験データを取得する場合、各実験条件を精査し、解析対象として妥当であるかを検証する作業が求められます。
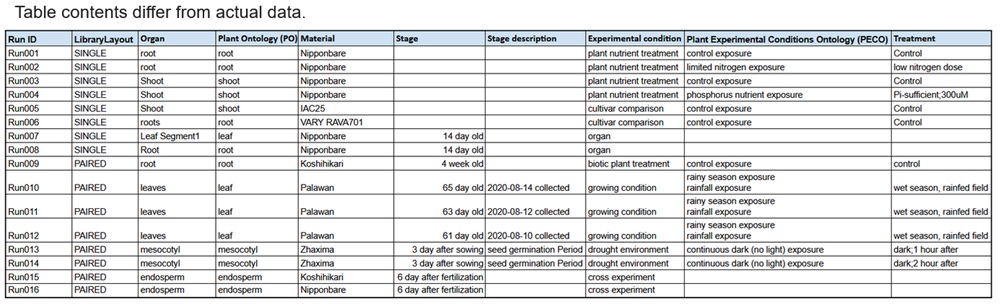
WGIでは、データベース上のモデル生物種についてRNA-seq実験の主要な実験条件の項目について調査し、
RNA-seq実験データの実験条件を表形式で整理
しています(
メタデータ化
)。
メタデータには、実験のID、材料、処理、生育ステージ、抽出部位などの情報が含まれます(下表参照)。
メタデータを活用することにより、データベース検索の場合と比較して、解析対象として妥当・的確な、より多数のRNA-seq実験データセット(ビッグデータ)を選抜できます。
結果として、
遺伝子探索を高精度化・高効率化
できます。
遺伝子発現行列
とメタデータを結合
することにより、表計算ソフトウェアや統計解析ソフトウェア上で
遺伝子発現プロファイルの横軸
を任意の実験条件(RNAの抽出部位や処理条件、実験系統など)で簡単にソート
可能となり、 発現プロファイルからの
遺伝子探索が高速化
します。
メタデータ作成は、WGIの熟練したキュレーターが実施しており、
動植物・微生物のいずれの種でも作成可能
です。
An Example of the RNA-Seq Metadata
◆オントロジーによるメタデータ作成による遺伝子探索の高精度・高速化
RNA-seqの実験条件の項目は、材料(系統・品種)、生育ステージ、部位、時刻、生育環境など多岐にわたります。
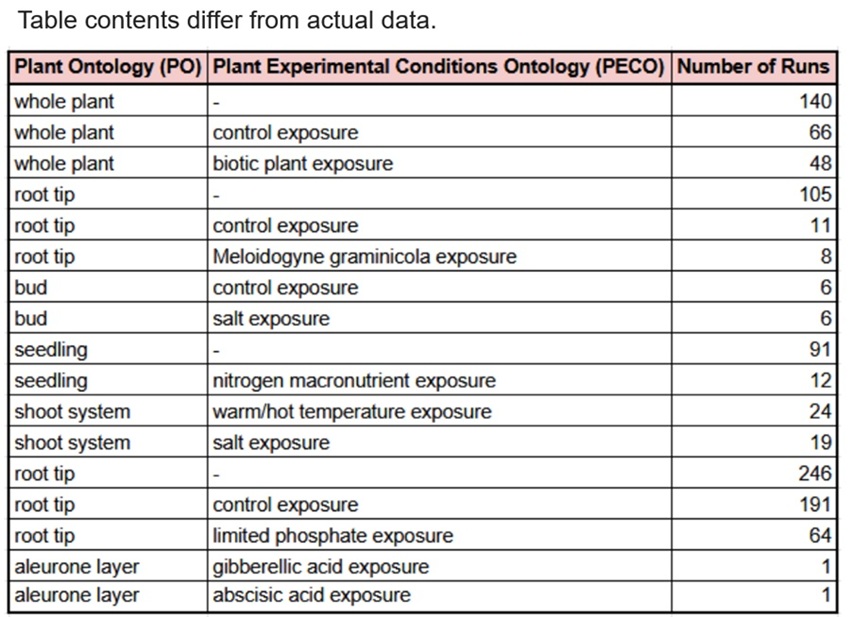
WGIでは、植物種の実験データでは、Plant Ontology (PO:植物の部位を表す)とPlant Experimental Conditions Ontology(PECO:実験処理を表す)を併用することで、 各RNA-Seqデータの詳細な分類・検索・抽出を可能としています(下表参照)。
動物・微生物種についても、植物種と同様に、
オントロジー(使用する用語の統一化)によるメタデータを作成
することで、
メタデータから目的とする実験条件のRNA-seq実験データの網羅的検索
を可能とします。
大規模RNA-Seqデータのメタデータ利用により、
どの遺伝子がどの時空間・環境条件で高発現しているかなどを正確かつ迅速に把握
できます。
An Example of the RNA-Seq Curation in a Plant Species
高品質な遺伝子発現行列の作出(Task D、E)
WGIでは、配列解読のクオリティーの高いリード、および、DNA領域をフィルタリングし、以降の解析に十分に活用できる高品質なリードのみを使用しています。 さらに、参照ゲノム配列などへのマッピング率などの統計量などから高品質な実験データのみを扱い、高精度な遺伝子探索を可能としています。
◆メタデータから高精度解析を可能とする実験データの選抜と遺伝子発現行列の生成、各種解析(Task D)
WGIの受託サービスでは、解析対象の生物種の
メタデータ
や
実験条件ごとの登録Run数表
を作成・提供します。
これらの
メタデータを用い、解析対象とするRNA-seq実験データを選抜
いただけることから、遺伝子探索など高効率・高精度な解析が可能となります。
解析対象種の興味対象の部位や処理を事前にお伝えいただけることにより、一般には膨大となるメタデータ情報量をスリム化できるため、選抜作業が容易となります。
WGIでは、決定された実験データ群を用いて遺伝子発現行列を作出し、納品いたします。
もちろん、
遺伝子発現行列を用いた各種解析
、たとえば、DEG群の選抜、発現プロファイルの類似性・相反性解析、候補遺伝子の機能情報の付与、異種との種間ホモログ(遺伝子ファミリー)などの情報解析も承ります。
◆独自のRNA-seqデータからの遺伝子発現行列の生成と各種解析(Task E)
ユーザー独自のRNA-seqデータからの
高品質な遺伝子発現行列
の作出・納品をいたします。
独自データに加えて、
オンラインのRNA-seqデータを統合した遺伝子発現行列
の作出も可能です(
Task D
との統合解析)。
もちろん、
遺伝子発現行列を用いた各種解析
、たとえば、DEG群の選抜、発現プロファイルの類似性・相反性解析、候補遺伝子の機能情報の付与、異種との種間ホモログ(遺伝子ファミリー)などの情報解析も承ります。
遺伝子発現行列からの目的遺伝子の高精度・迅速・低コストな探索
(Task D、Eと組み合わせ自由な解析オプション)
遺伝子発現行列
を活用することにより、様々なアプローチにより、目的の候補遺伝子(群)を探索することができます。
◆時空間特異的な発現遺伝子やDEG群の探索
時空間特異的な発現遺伝子群は重要な機能を担うマスター遺伝子などの候補となります
遺伝子発現表列から、たとえば、1つ以上のRNA抽出条件(部位、生育環境条件など)のみで発現する、または、高発現する
時空間特異的な発現遺伝子群
を遺伝子発現行列から統計的・高精度に抽出できます。
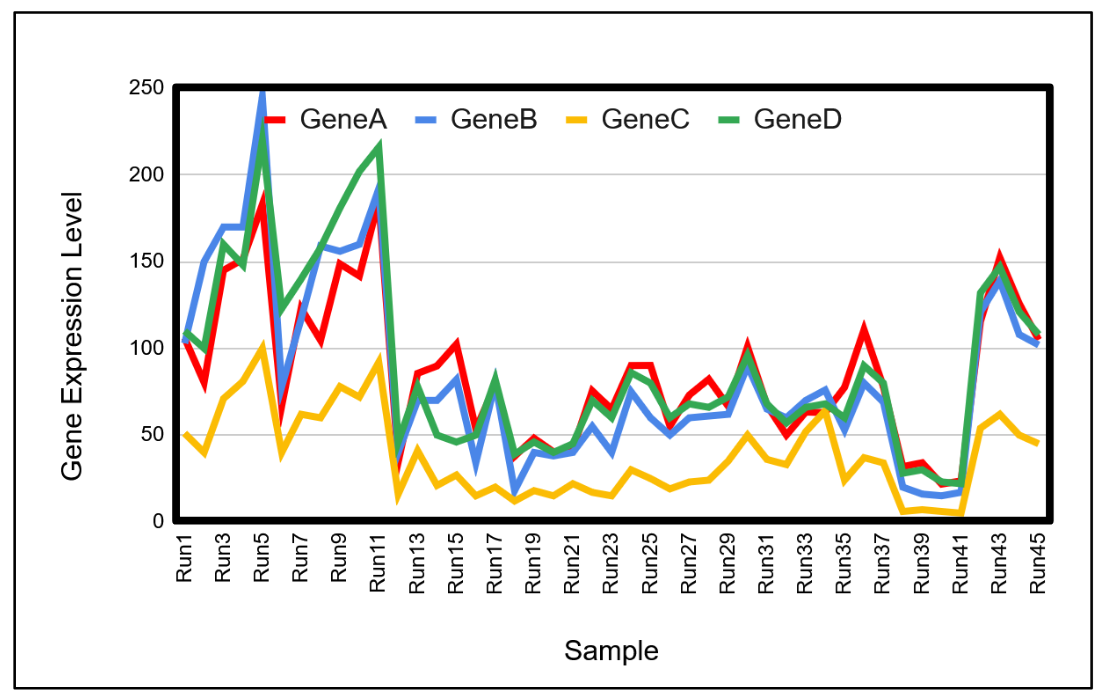
たとえば、
下図
は、花で特異的に高発現している遺伝子を示します。
WGIでは、
RNA-seq実験データのメタデータ
を作成・活用するため、同一条件の実験データを最大数取得し、反復実験として扱うことができます。
そのため、1つの対照実験データからのみ目的遺伝子を探索する場合と比較して、
高い再現性・精度で目的遺伝子群を抽出
できます。
また、
従来のDEG探索法
では、
候補遺伝子群を十分に絞り込むことができません
。
そのため、WGIでは、
DEG遺伝子群の高精度抽出のための独自のAI解析基盤
を活用し、特異的な発現プロファイルを示す遺伝子を探索可能としています。
WGIでは、DEG遺伝子群や時空間特異的な発現遺伝子群を高精度に探索するために、
メタデータを活用
するのみではなく、
独自の統計解析基盤を整備・活用
しています。
そのため、データベースからの実験データの取得から従来の統計手法を利用する
一般的なアプローチでは得られない高精度な候補遺伝子
の情報を取得できます。
An Example of a Specifically Expressed Genes
◆関与する生物学的プロセスや発現制御機構が同一・類似する候補遺伝子群の高効率選抜(Task F)
遺伝子発現プロファイルが類似する遺伝子群
(
下図
)は、発現量が上昇・下降する時空間や環境条件が同一であることから、 生物学的に意味のある遺伝子群と考えられます。
たとえば、
関与する生物学的プロセスが同じ
(例:配偶子形成、同じ代謝プロセス)、 または、
発現を制御する転写因子とシス因子が同じ・類似
することが示唆されます。
また、ある既知の遺伝子と共働する遺伝子を探索する場合、既知遺伝子と発現プロファイルが類似する遺伝子群が候補遺伝子群となります。
高発現する実験条件群から、
遺伝子が発現・機能する時空間・処理条件
を推察できます。
WGIでは、発現プロファイルが類似する遺伝子群を
短時間・高精度・低コストに同定するための独自のAI・DX解析基盤
を整備・活用しています。
従来の2つの遺伝子間の発現プロファイルの
相関解析に基づく手法
(共発現解析)では、
偽陽性を含む
こと、
計算時間とメモリーを多く消費
することに加えて、
精度と効率の点から不適当
です。
An Example of Similar Gene Expression Profiling
◆負のフィードバック機構の関連遺伝子群や同一基質に作用する酵素遺伝子群などの高効率探索(Task F)
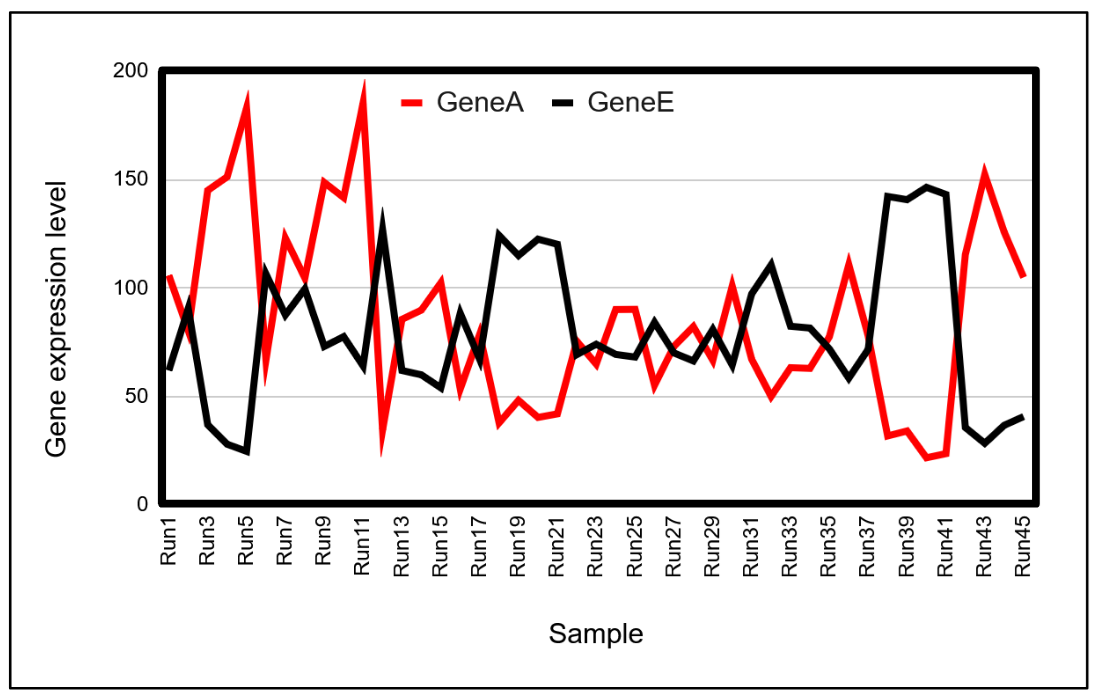
発現プロファイルが相反する遺伝子群
(
下図
)は、
負のフィードバック
の関係にある遺伝子群などと推察されます。
たとえば、
同一の代謝前駆体を基質とする異なる酵素をコードする遺伝子群
が存在する場合、 酵素活性(遺伝子発現量)の高い酵素ほど前駆体化合物を優先的に消費するため、
前駆体の利用においてトレードオフ(相反関係)が生じる
可能性があります。
このような遺伝子群では、発現プロファイルに相反関係が生じる可能性があります。
発現プロファイルの相反性に関する情報は、負のフィードバック機構の解明や、同一の前駆体に作用する酵素遺伝子群の同定などに有効です。
高発現・低発現する実験条件群から、
負のフィードバックやトレードオフの制御条件
を推察できます。
WGIでは、発現プロファイルが相反する遺伝子群を
短時間・高精度・低コストに同定するための独自のAI・DX解析基盤
を整備・活用しています。
従来の2つの遺伝子間の発現プロファイルの
相関解析に基づく手法
(共発現解析)では、
偽陽性を含む
こと、
計算時間とメモリーを多く消費
することから、
精度と効率の点から不適当
です。
An Example of Reciprocal Gene Expression Profiling
◆従来法により発現プロファイルが類似・相反する遺伝子群の探索
発現プロファイルは類似性・相反性を示す遺伝子群の探索には、従来、主に、相関解析(相関係数)が用いられています。
相関解析を主たる解析アプローチとすることは偽陽性などの
リスクから推奨されません
が、参考情報として活用できます。
相関係数以外に、ユークリッド距離などを用いることも可能ですが、大規模な計算コスト(時間やメモリー)が必要となります。
◆遺伝子の生物学的機能に関する知見(知識情報)の付与(Task B, C)
広く用いられているDNA/アミノ酸配列の類似性解析による機能予測結果は、
推定された機能に生物学的根拠がない
ため、遺伝子探索において積極的に活用できません。
広く用いられてい候補遺伝子群機能アノテーションに対するエンリッチメント解析は、
統計処理上の問題点
があります。
従来のDNA/アミノ酸配列の類似性解析やエンリッチメント解析は参考情報としては活用できますが、機能推定の根拠がないため、遺伝子探索の効率を低下させる要因となっています。
WGIでは、参考情報としての機能予測結果(配列類似性解析、エンリッチメント解析)に加えて、より信頼度の高い
遺伝子機能の知見(知識情報)
をWGI独自のAIテキストマイニング(A2K/LA2K)技術により付与できます。
A2K/LA2K解析に利用可能な査読付き論文のAbstractビッグデータやテキストから、遺伝子の機能、代謝、発現制御、環境応答などの知識情報を得ることができます。
◆遺伝子のタンパク質機能ドメイン情報と種内・種間ホモログ(遺伝子ファミリー)情報の付与(Task G, H)
従来のDNA/アミノ酸配列の類似性解析による機能予測には偽陽性が多く含まれる
ため、 従来法に加えて、より信頼度の高い
機能ドメインレベルでの機能情報
を付与できます(Task G)。
WGIでは、機能ドメインや配列パターンの類似性に基づく遺伝子ファミリー分類を行っており、ファミリー情報により生物学的機能や発現制御機構の類似性が示唆されます(Task H)。
◆遺伝子の発現制御因子:転写因子・シス因子の情報の付与(Task B, C, I)
WGIでは、独自の
AIテキストマイニング手法(Task B, C)
、および、
AI駆動型の配列解析技術(Task I)
により、遺伝子の発現制御因子の情報を集積しています。
◆遺伝子-化合物などのネットワーク構築
遺伝子や化合物(代謝産物など)の関係性を
ネットワーク
により視覚化します。
フリーのネットワーク描画・閲覧・編集ソフトにより、提供されるネットワーク情報から遺伝子や化合物の関係性を迅速・容易に把握でき、機能が未知である遺伝子の機能推定などを加速化できます。
関係性としては、DNA/アミノ酸配列の類似性、発現プロファイルの類似性・相反性、高発現する時空間、関与する形質・代謝経路、転写因子、種内・種間ホモログなどがあります。
種内・種間ホモログ
についても上記の情報を付与できることから、関連づけられた遺伝子の情報を種横断的に活用でき、遺伝子探索のために活用できる情報量を最大化できます。